Treatments in statistics refer to the different levels or conditions applied in an experiment. These factors are manipulated to observe their impact on the dependent variable.
Exploring the realm of statistics unveils the pivotal concept of treatments, a term that signifies the variants under experimental scrutiny. Researchers rely on treatments to deduce the effects of one or more independent variables on an observable outcome, often called the dependent variable.
With a firmly established experimental design, distinct treatments can illuminate causal relationships or discern patterns in complex data sets. This methodology plays a crucial role across disciplines, from medicine, where treatments might be new drugs, to agriculture, where they could be fertilizer types. Proper application and control of treatments ensure the reliability and validity of statistical conclusions, making them an indispensable tool in scientific inquiry. As statistics continues to drive decision-making processes in various sectors, comprehending treatments is essential for anyone delving into data analysis.

Credit: eightify.app
The Essence Of Treatments In Statistics
The essence of treatments in statistics lies at the heart of turning raw data into actionable knowledge. ‘Treatments’ in a statistical sense are not about medical interventions, but rather about the specific conditions applied in experimental scenarios. Each treatment represents a unique combination of factors under study that can lead to influential insights.
Treatments: Bridging Data And Decisions
Understanding treatments becomes crucial for decision-makers. Treatments help frame the experiments that give reliable results. These results then guide smart decisions in fields ranging from healthcare to marketing. Without well-defined treatments, data may lead to poor decisions:
- Clarity: They make experiment variables clear.
- Comparability: They allow comparison under controlled settings.
- Confidence: They provide a basis for statistical confidence in the results.
The Role Of Treatments In Experimental Design
Every experiment needs a strong design to ensure useful results. The role of treatments in experimental design is to test hypotheses accurately:
- Definition: They clearly define what is being tested.
- Implementation: They ensure consistent application across samples.
- Analysis: They aid in dissecting data for clear conclusions.
Recognizing these roles helps scientists and researchers reduce bias and increase the validity of their conclusions. A solid understanding of treatments turns experiments into a robust backbone for statistical analysis.
Unlocking The Mysteries Of Data With Treatments
Data holds secrets to countless questions. Like keys, treatments in statistics unlock these mysteries. They clarify data, making valuable insights burst forth. This post dives into the world of statistical treatments. It paves the path to understanding complex data interactions.
Illuminating The Unknown: Data And Treatment Interactions
Interactions shed light on hidden correlations. Think of it as detective work. Experts use variables to reveal patterns within mountains of data.
- Data behaves differently under varying conditions.
- Interactions can explain why these changes occur.
- They can also predict future data behaviors.
- Interactions highlight cause-and-effect relationships.
This knowledge is critical. It guides decision-making in fields as diverse as medicine and economics.
Crucial Insights Through Controlled Experimentation
Controlled experiments are the bedrock of reliable data analysis. By controlling variables, scientists test hypotheses accurately. This approach is essential for gathering dependable data insights.
These experiments can include:
| Treatment Type | Examples |
|---|---|
| Randomized | Drug trials, A/B testing |
| Non-randomized | Observational studies |
Each treatment type serves a unique purpose. Randomized treatments minimize bias. Non-randomized treatments offer insights when randomization is not possible.
Types Of Treatments In Statistical Analysis
Understanding the different types of treatments in statistical analysis is key to proper data interpretation. Treatments influence outcomes and their analysis helps in decision making. Let’s explore the variations in treatments and their implications.
Categorical vs. Continuous TreatmentsCategorical Vs. Continuous Treatments
In statistics, treatments can take various forms. The nature of these treatments impacts the analysis approach.
- Categorical treatments are based on distinct groups or categories. Examples include gender, type of medication, or brand preferences.
- Continuous treatments, in contrast, involve measurements on a scale. Think of dosage levels, temperature, or time spent studying.
| Type of Treatment | Examples | Typical Data Analysis |
|---|---|---|
| Categorical | Gender, Medication Type | Chi-Square, ANOVA |
| Continuous | Dosage, Temperature | Regression, Correlation |
Fixed Vs. Random Effects
Treatments also differ based on how they are applied in the study design. This affects the analytical models used.
- Fixed effects are specific, known levels of a treatment. They are constants in a study. For instance, a fixed diet program in a weight loss study.
- Random effects come from a larger population. They represent a random sample. For example, the effect of different teachers on student performance.
| Effect Type | Characteristics | Statistical Models |
|---|---|---|
| Fixed Effect | Known, Specific Levels | Mixed Model, ANOVA |
| Random Effect | Random Sample from Population | Generalized Linear Models |

Credit: ppimhs.org
Designing Experiments: The Building Blocks
Designing experiments in statistics stands as the foundation for drawing credible conclusions. Solid experimental design translates theories into actionable insights. This process involves crafting a treatment plan and strategically allocating treatments to balance bias and variability.
From Theory To Action: Creating A Treatment Plan
A well-crafted treatment plan is a catalyst that turns a theoretical framework into empirical evidence. The steps to create such a plan are simple:
- Define the objectives: Know what the experiment must achieve.
- Select treatments: Choose variables that can lead to informative results.
- Determine levels: Decide the different states or values those treatments can take.
Effective treatment plans serve as roadmaps, guiding researchers from hypotheses to tested, real-world applications with clarity and precision.
Balancing Bias And Variability In Treatment Allocation
In the realm of experiment design, striking a balance between bias and variability is critical for reliability. The two pillars to achieve this balance include:
- Randomization: Assign treatments randomly to prevent systematic errors.
- Replication: Duplicate the experiment to minimize random errors and boost confidence.
This methodology ensures that results are neither skewed by predilections nor muddled by anomalies, providing a clear, unbiased view of an experiment’s outcomes.
| Step | Action | Purpose |
|---|---|---|
| 1 | Define Objectives | Direct the focus of the research |
| 2 | Select Treatments | Identify variables to test |
| 3 | Determine Levels | Set variations for robust analysis |
| 4 | Implement Randomization | Reduce systemic bias |
| 5 | Execute Replication | Validate results through repetition |
Evaluating Treatment Effects
Understanding treatment effects is a core objective in statistical analysis. Whether in medicine, psychology, or economics, assessing the impact of a specific treatment is critical to decision-making. Statisticians use a variety of methods to determine whether treatments have significant effects and how substantial these effects are.
Statistical Significance: Beyond The P-value
Statistical significance indicates if an effect is likely not due to chance. Typically, a p-value less than 0.05 suggests significance. But, the story doesn’t end with p-value alone. Let’s explore why.
- P-value Misinterpretations: Small p-values don’t always mean big effects. They might occur with minor differences if the sample size is large.
- Sample Size: Larger samples can detect smaller differences, influencing p-value results.
- Context Matters: Understanding the field of study helps interpret p-values. A p-value in a medical trial could have different implications than one in a market research study.
Effect Size And Practical Significance
The effect size measures the strength of the relationship between variables. Unlike the p-value, the effect size quantifies the extent of an effect, helping us understand its practical importance:
| Effect Size (Cohen’s d) | Interpretation |
|---|---|
| 0.2 | Small effect |
| 0.5 | Medium effect |
| 0.8 | Large effect |
Understanding both effect size and p-value contributes to a bigger picture:
- Real-world Impact: A treatment could have a statistically significant effect but not a meaningful one in practical scenarios. Effect size helps us identify this.
- Comparing Studies: Effect size allows comparisons across studies, even if they have different sample sizes or measures.
Advanced Treatment Analysis Techniques
Treatment analysis helps us understand the impact of interventions in statistics. But as data grows more complex, standard methods fall short. Luckily, advanced analysis techniques offer deeper insights. We’ll explore two such powerful methods.
Multivariate Approaches In Exploring Data Treatments
Multivariate approaches capture relationships between several variables at once. Unlike univariate analysis, these techniques handle complex, multi-dimensional data. This makes findings more robust and accurate.
- Principal Component Analysis (PCA) – reduces data complexity.
- Factor Analysis – finds hidden variables in data.
- Cluster Analysis – groups similar data points together.
- Discriminant Analysis – distinguishes between categories.
- Canonical Correlation – links two data sets.
By using these techniques, analysts can unravel the intricate effects of treatments on multiple outcomes. This leads to stronger conclusions and better decision-making.
Hierarchical Linear Models For Complex Data
Hierarchical Linear Models (HLMs) are made for nested data. Think of students within classes or patients within hospitals. Standard methods can’t handle this well. HLMs can.
| Level | Example |
|---|---|
| Level 1 | Individual data (e.g., student test scores) |
| Level 2 | Group data (e.g., class teaching methods) |
HLMs provide precise estimates by considering data hierarchy. This makes them ideal for policy analysis, educational research, and health studies.
Challenges In Treatment Application
Statistics help us understand and improve the world around us. But using treatments in statistics is not always easy. Experts face several challenges when applying statistical treatments to real-world problems. Let’s look at these challenges.
Dealing With Confounding Variables
Confounding variables often confuse our results. They make it hard to tell if a treatment caused an outcome. Imagine testing a new drug. If patients also change their diet, how do we know what worked?
- Identify: Pick out all possible confounders before the study.
- Control: Use random assignment or matching techniques.
- Measure: Collect data on confounding variables.
- Adjust: Use statistical methods like regression to correct estimates.
Experts must be careful. They keep an eye on everything that might affect their studies.
Complexities In Longitudinal Data Treatments
Longitudinal studies track the same subjects over time. They help us see changes caused by treatments. Yet, these studies can be complex.
| Challenge | Solution |
|---|---|
| Missing Data | Use multiple imputation or models accounting for missingness. |
| Time-Dependent Confounding | Employ methods like time-varying covariates adjustment. |
| Changes Over Time | Consider mixed-effect models or growth curve analysis. |
Longitudinal studies need special attention. That way, we can trust the results they give us.
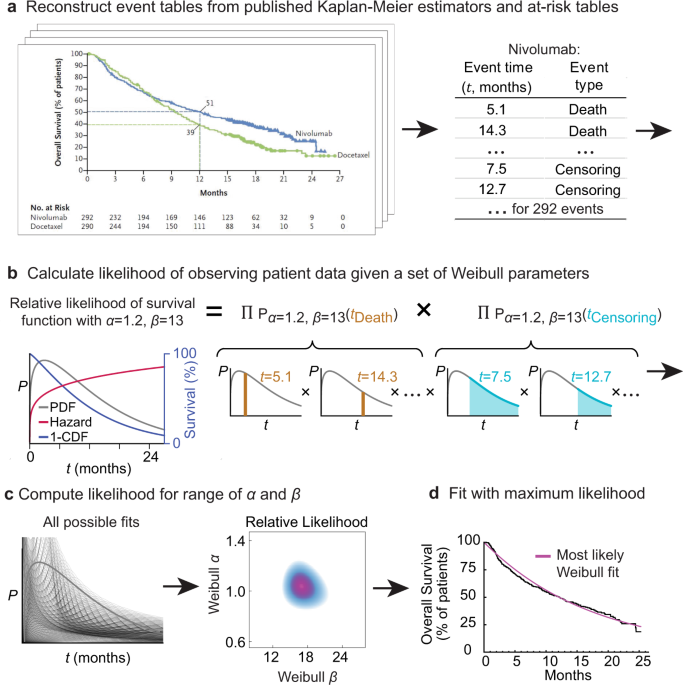
Credit: www.nature.com
Case Studies: Treatment Success Stories
Welcome to our spotlight on ‘Case Studies: Treatment Success Stories’. The realm of statistics is teeming with real-world scenarios where data treatments have spurred significant advancements. From healthcare to retail, we unveil how strategic statistical treatments can turn data into powerful, actionable insights. Let’s explore some success stories that underline the transformative power of these treatments.
Revolutionizing Industries With Strategic Data Treatment
Industries across the globe have witnessed profound changes. This shift is largely due to strategic data treatment. Firms now harness valuable insights, propelling them ahead of competitors.
- Healthcare: Patient outcomes have greatly improved. This is a result of predictive models from treated datasets.
- Retail: Inventory management became more efficient. It’s all thanks to data treatments identifying purchase patterns.
- Fintech: Fraud detection systems grew more robust with treated data. This led to fewer financial crimes.
Each sector benefits from crafting tailor-made strategies. These strategies stem from a deep dive into their data pools.
Cutting-edge Research And The Role Of Treatments
Scientific advancement relies on cutting-edge research. Treatments in statistics play a crucial role in driving this progress.
- Data treatments clarify complex biological data. This leads to breakthroughs in medical research.
- They refine data for environmental studies. This helps in predicting climate change trends accurately.
- Enhancing market research data has improved consumer products.
Researchers can achieve clearer outcomes with polished datasets. Thus, treatments stand indispensable in pioneering research.
Future Of Treatments In An Era Of Big Data
The landscape of statistical treatments is undergoing a dramatic change. Big Data has revolutionized the way we approach data analysis. Unprecedented volumes of data offer new insights and superior predictive capabilities. Let’s dive into how this data-rich era is reshaping statistical treatments.
Predictive Analytics And The Evolving Treatment Landscape
Predictive analytics harnesses big data to forecast trends and behaviors. This innovation benefits a wide range of fields, from healthcare to marketing. It allows professionals to make informed decisions by anticipating future outcomes. The benefits of such analytical power are immense:
- Improved Accuracy: More data points mean finer insights.
- Faster Decisions: Real-time data analysis accelerates response times.
- Proactive Measures: Foreseeing issues allows for pre-emptive strategies.
Embracing Machine Learning In Statistical Treatments
Machine learning is a subset of artificial intelligence that learns from data without being explicitly programmed. Its integration into statistical treatments is nothing short of transformative:
| Aspect | Impact of Machine Learning |
|---|---|
| Data Processing | Manages large volumes swiftly and accurately. |
| Pattern Recognition | Uncovers subtle correlations and causalities. |
| Modeling Precision | Enhances model’s predictive performance. |
Consequently, machine learning is crucial for extracting valuable insights from complex data sets. Its ability to learn from new data continually refines statistical models. This dynamic nature keeps treatments relevant and effective in the face of evolving data trends.
Frequently Asked Questions On Treatments In Statistics
What Is An Example Of Treatment In Statistics?
An example of treatment in statistics is a specific dosage of a medication given to a group during a clinical trial.
What Is A Treatment In An Experiment In Statistics?
A treatment in an experiment is any condition applied to subjects or units to measure its effect on a response variable.
What Are Treatment Factors In Statistics?
Treatment factors in statistics refer to independent variables manipulated by researchers to determine their effect on study outcomes. They are central to experimental designs, influencing the dependent variable’s responses.
What Are Levels Of Treatment In Statistics?
Levels of treatment in statistics refer to the different conditions or groups that experimental units are assigned to in a study. These have several categories or intensities for variables being tested.
What Are Common Statistical Treatments?
Statistical treatments often include techniques like ANOVA, regression analysis, t-tests, and chi-square tests, each suited for different types of data and research questions.
How Do Treatments Differ In Statistics?
In statistics, treatments differ based on data types and research goals; they can be descriptive, inferential, or predictive, guiding decision-making based on data behavior.
Conclusion
As we wrap up our exploration of statistical treatments, remember their crucial role in data analysis. By understanding various techniques, we unlock deeper insights within data sets. Embrace these tools to enhance research quality and drive evidence-based decisions. Keep learning, stay analytical, and harness statistics for success.